Summary
World models predict future observations conditioned on an input action. For complex embodiments such as a human agent, these actions may require specifying motion for each individual joint, greatly increasing the model's input dimensions. This high-dimensionality makes world models difficult to control manually and exponentially more expensive for search-based planning methods like Cross-Entropy Method (CEM).
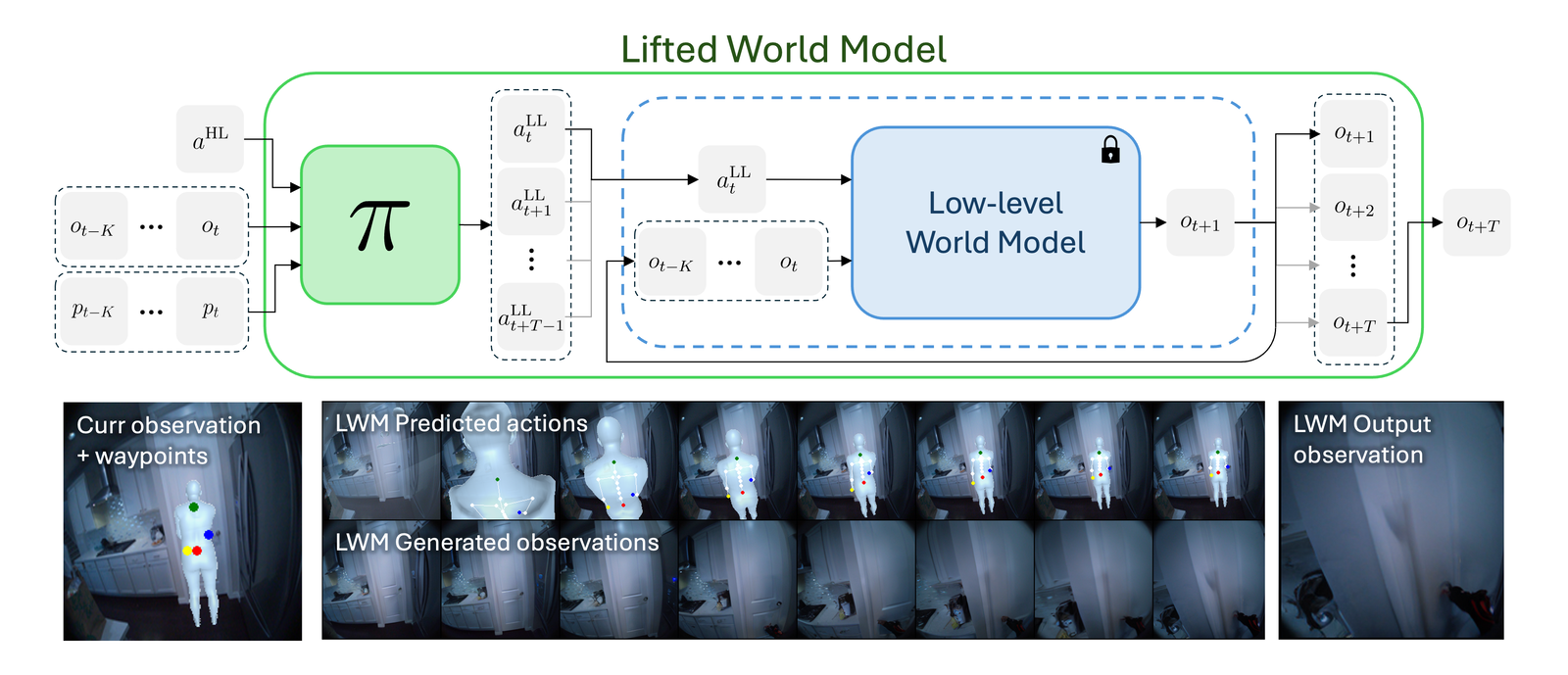
Our solution to this problem is to lift the world model to a higher level of abstraction. We train a lightweight policy to map a high-level action to sequences of low-level actions. Composing this policy with a frozen world model creates a Lifted World Model (LWM) that predicts a longer-horizon future observation from a single high-level action. This lifting reduces the dimensionality and length of action sequences without the need to finetune or change the world model.
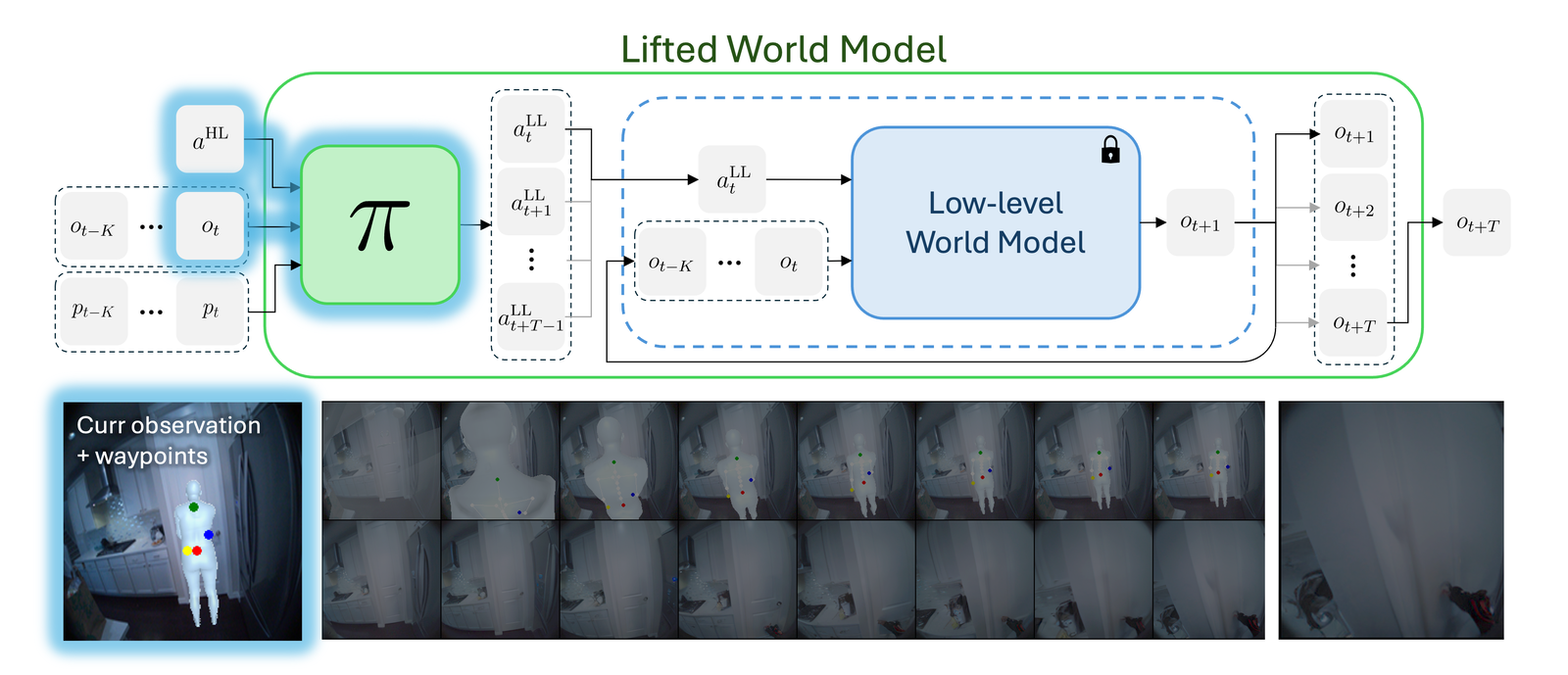
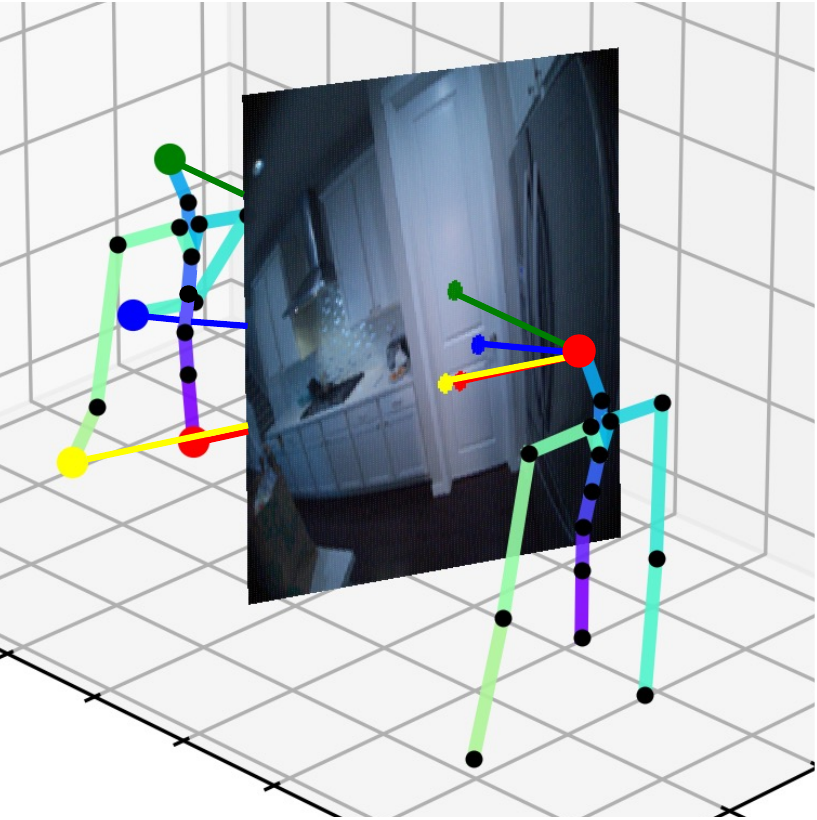
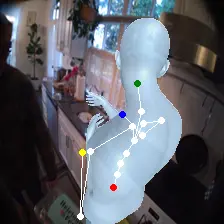
For an egocentric, embodied agent, we introduce waypoints as high-level actions. Each waypoint is a 2D projection of a 3D goal position onto the current observation and is specified for each leaf joint of the embodiment: the pelvis, head, left-hand, and right-hand. Importantly, waypoints are interpretable, low-dimensional, easy to specify and easy to search over.
We explore using waypoints as goal-conditioning for our policy compared to using goal observations and find that waypoints better capture the desired goal pose. We also combine our policy with a PEVA world model and perform CEM planning in high-level waypoint space for an embodied human agent. We find that planning with the LWM reduces mean joint error (MJE) by 3.8× compared to planning in low-level joint space. Our method also performs better at various CEM compute budgets and across longer goal horizons and longer initial distances to the goal pose. For additional experiments on waypoint visibility, ablations using 3D waypoints, decomposing action generation, as well as planning with 3D waypoints and in unseen environments, see our paper.
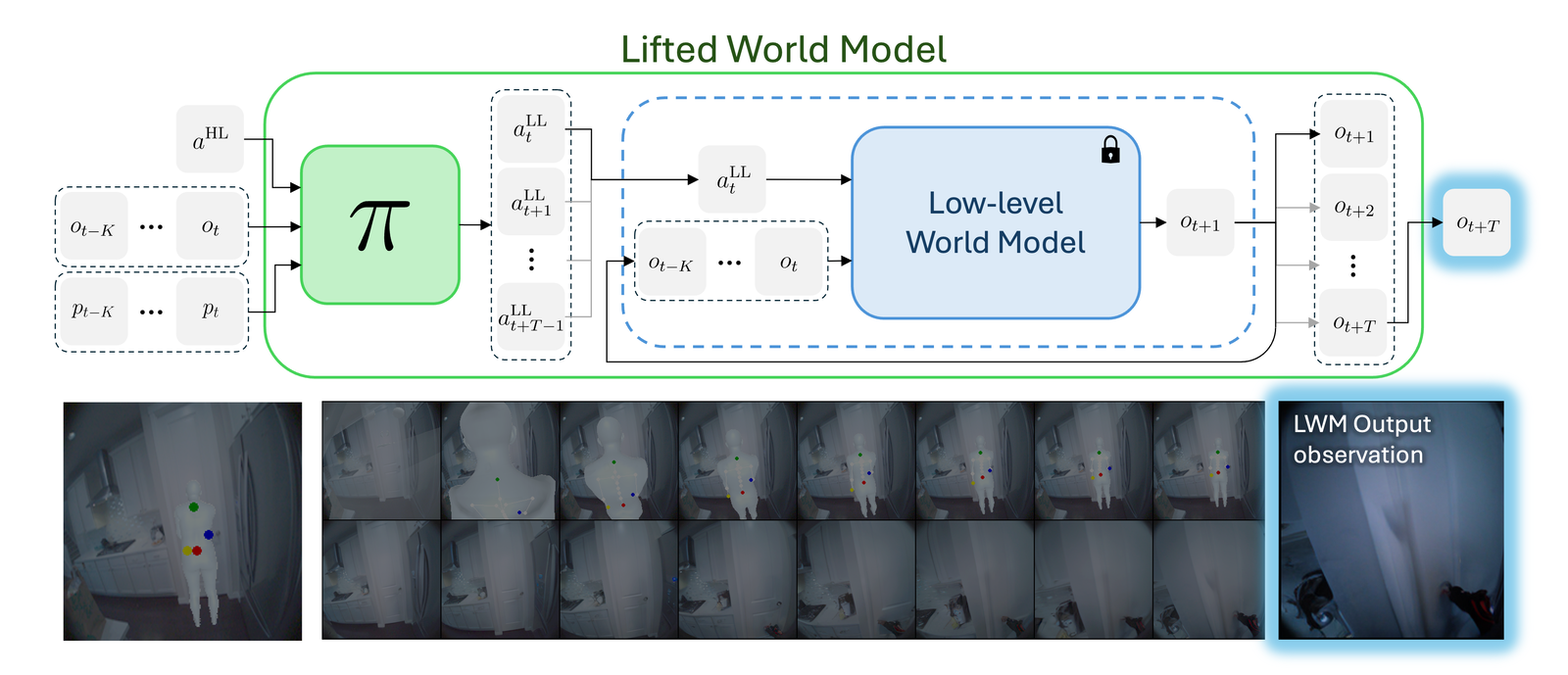
Method
Here we introduce the three components of our method: a high-level waypoint action space for controlling egocentric, embodied agents, a waypoint-conditioned policy that predicts sequences of low-level joint actions, and combining the policy with a low-level PEVA world model to form a Lifted World Model (LWM) for planning and control.
High-level Waypoint Actions
Each waypoint is the 2D projection into the current observation ot of a near-term 3D goal position for one leaf joint of the embodied agent. For the human XSens embodiment, we use one waypoint for each leaf joint (pelvis, head, left-hand, right-hand), all drawn directly on the current frame. We sample goal poses 8 timesteps (2 seconds) into the future. This reduces the action space dimensionality from 8 timesteps × 48 joint action dimensions for PEVA to just 4 × 2 = 8 dimensions for our high-level Lifted World Model.
During training, ground-truth waypoints are obtained by projecting the goal pose pg onto observation ot via forward kinematics and the camera matrix. At test time, waypoints can be specified manually by the user or searched for with CEM.

Goal-Conditioned Policy
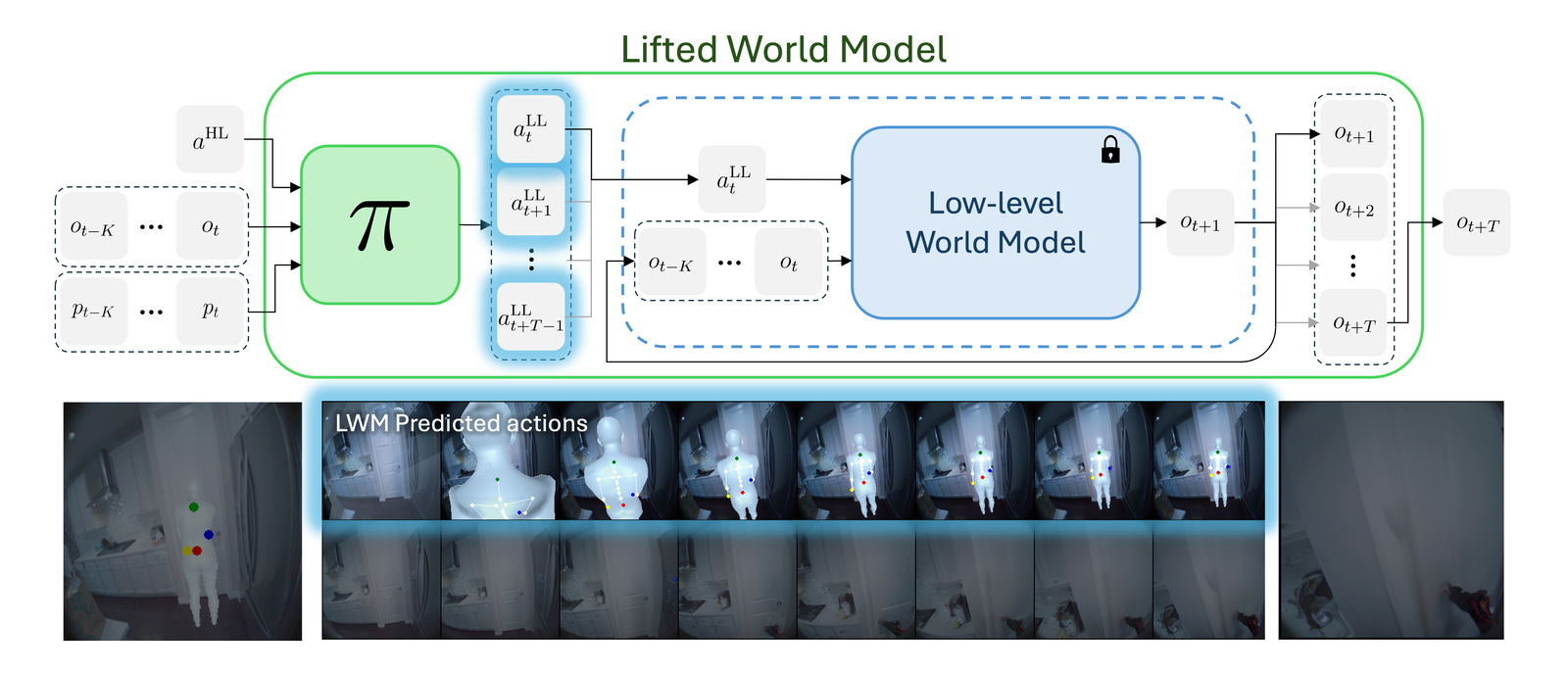
Conditioned on a high-level waypoint action, the policy uses image and pose context to infer a meaningful sequence of T=8 low-level joint actions. The policy uses this context and the relative spacing of the waypoints to infer and move towards a 3D goal pose. It also handles sparse or out-of-frame waypoints — for example, specifying only a pelvis waypoint for navigation — inferring the unspecified joint targets from context.




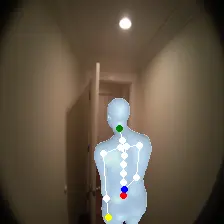
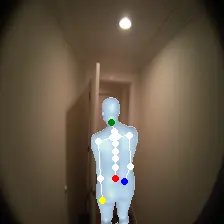





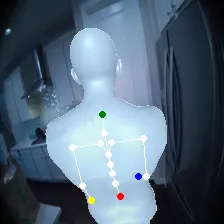
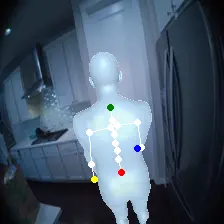




































Lifted World Model and Search
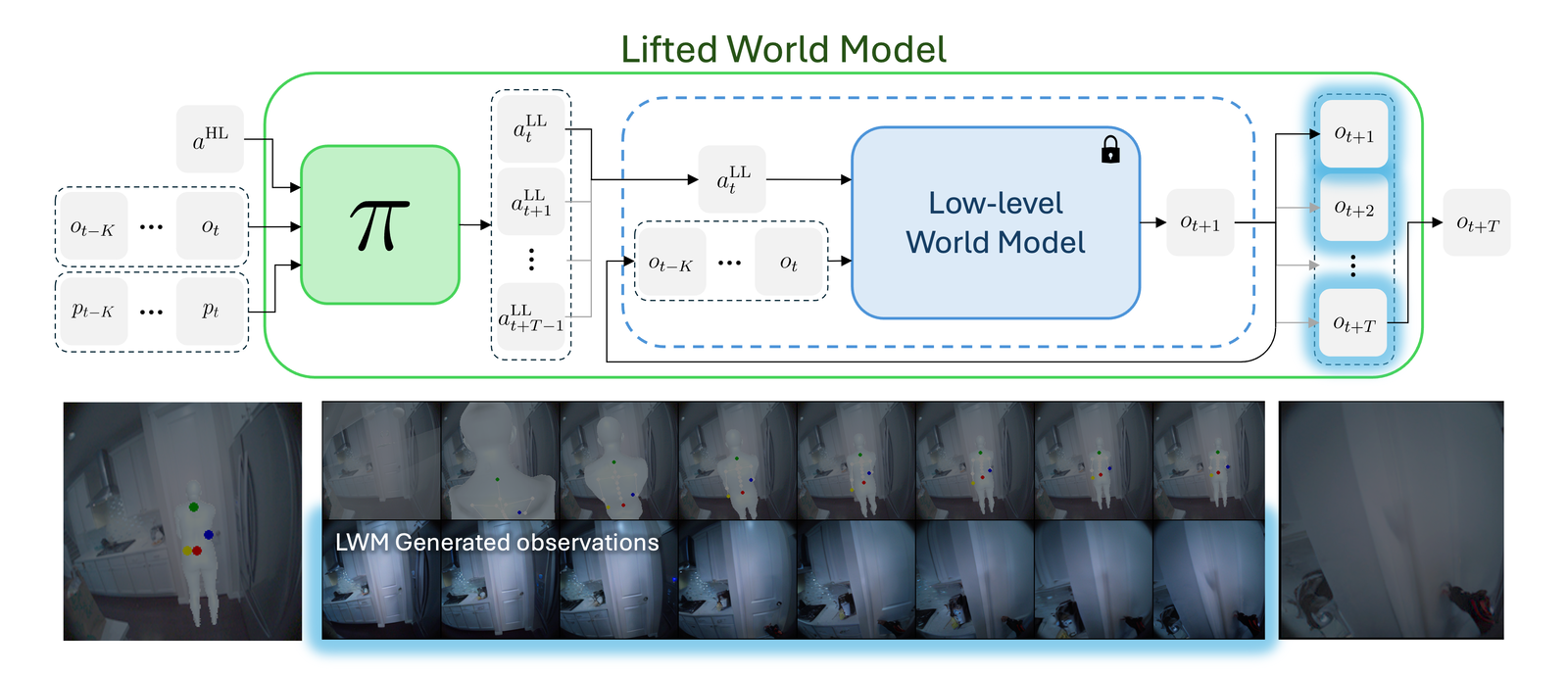
Composing the policy with the frozen low-level world model yields an LWM, which predicts ot+T from ot, pose context, and a single high-level action. With the LWM we can run CEM planning in high-level action space by sampling waypoints, simulating the predicted goal observation, and updating the waypoint prior using the best performing trajectories.

Experimental results
We evaluate on the Nymeria dataset of egocentric human motion. Performance is measured by mean joint error (MJE) in meters between the final predicted pose and the ground-truth goal pose. MJE is reported for leaf joints, intermediate joints, and all joints together.
Goal-Conditioned Policy
We evaluate the policy on both unconditioned (no goal information) and goal-conditioned action generation. Conditioning on a goal observation og barely improves MJE: the NoMaD-style baseline reduces all-MJE by only 1.3 cm over unconditioned generation. In comparison, waypoints are an effective goal-conditioning signal; waypoint conditioning improves goal-conditioned all-MJE by 8.8 cm over unconditioned generation. Removing goal masking further improves goal-conditioned performance, at the cost of unconditioned MJE. Since we prioritize goal-conditioned generation to lift the world model, we adopt this no-masking policy going forward.
| Model | Unconditioned MJE | Goal-conditioned MJE | ||||
|---|---|---|---|---|---|---|
| Leaf | Int. | All | Leaf | Int. | All | |
| Initial distance (no action) | 0.445 | 0.419 | 0.426 | 0.445 | 0.419 | 0.426 |
| Random weights (untrained net) | 0.749 | 0.707 | 0.718 | 0.735 | 0.692 | 0.703 |
| Base policy (NoMaD) | 0.427 | 0.397 | 0.405 | 0.414 | 0.384 | 0.392 |
| + architecture | 0.406 | 0.375 | 0.384 | 0.388 | 0.359 | 0.367 |
| + pose context | 0.359 | 0.329 | 0.337 | 0.343 | 0.316 | 0.323 |
| + waypoint conditioning | 0.353 | 0.323 | 0.331 | 0.262 | 0.236 | 0.243 |
| + no masking | 0.437 | 0.408 | 0.415 | 0.243 | 0.219 | 0.226 |
Qualitatively, the policy generalizes well to counterfactual waypoints not present in the data. It is also context sensitive: the policy can use image and pose context to generate sensible actions in different scenarios using the same waypoints.


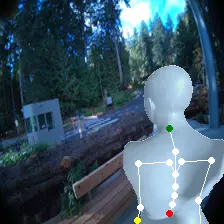
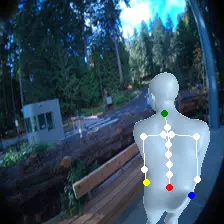





















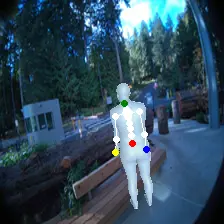














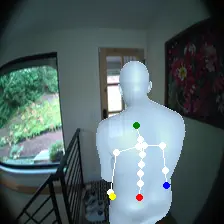




Lifted World Model Planning
We perform search-based planning using our LWM. We sample 128 hybrid navigation + interaction tasks from Nymeria and compare direct CEM in the joint action space (PEVA CEM) against CEM in the high-level waypoint space using our Lifted World Model (Lifted CEM). PEVA CEM reduces all-MJE by only 8.8 cm while Lifted CEM reduces it by 33 cm. Lifted CEM also beats every policy-only baseline (unconditioned, image-conditioned, and hierarchical) and a variant that searches over 3D waypoints instead of 2D.
| Method | Planning MJE | ||
|---|---|---|---|
| Leaf | Int. | All | |
| Initial distance (no action) | 0.724 | 0.697 | 0.704 |
| Unconditioned policy | 0.677 | 0.641 | 0.650 |
| Image-cond. policy (NoMaD) | 0.605 | 0.578 | 0.585 |
| Hierarchical policy (HDP) | 0.540 | 0.502 | 0.512 |
| PEVA CEM (joint space) | 0.637 | 0.608 | 0.616 |
| Lifted CEM (3D waypoints) | 0.453 | 0.407 | 0.420 |
| Lifted CEM (ours) | 0.411 | 0.359 | 0.374 |












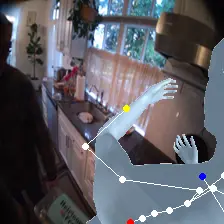
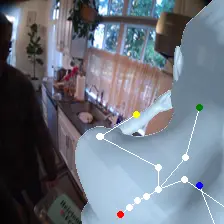
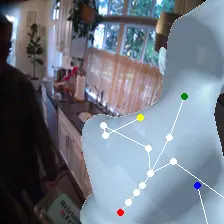
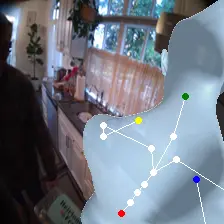
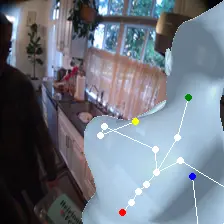
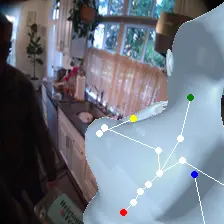




























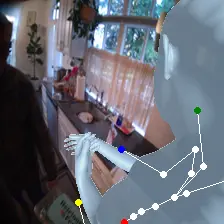
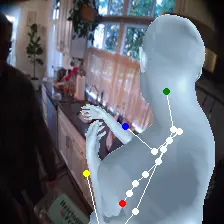





















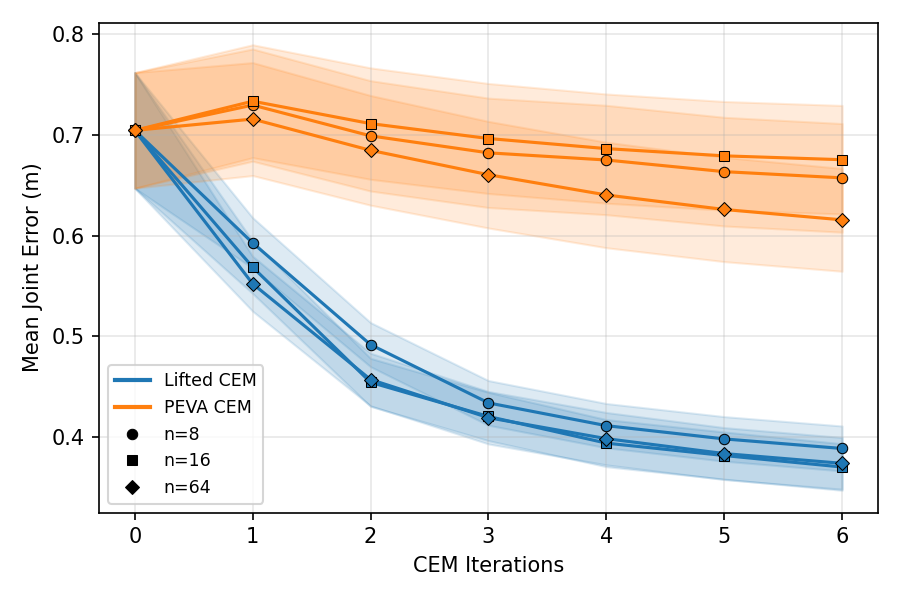
Lifted CEM also scales better with compute: it outperforms PEVA CEM at every CEM-iteration / sample budget tested. PEVA CEM in joint space performs worse after one CEM step, illustrating how naive search struggles in high-dimensional action spaces.
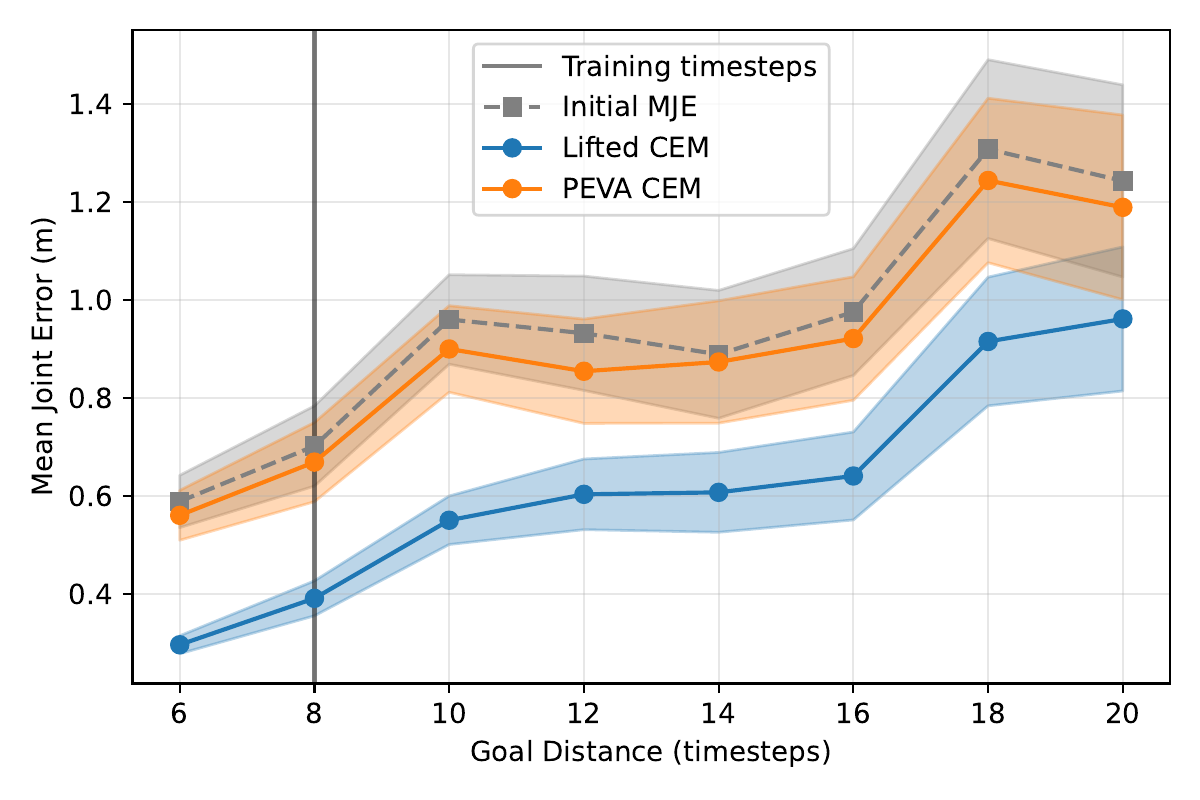
Varying Goal Horizons
We compare Lifted CEM and PEVA CEM when goals are sampled from varying time horizons and at varying distances. PEVA CEM is allowed to vary its plan length to match the horizon; Lifted CEM only predicts 8 timesteps, matching the pretrained policy's training horizon. We find that Lifted CEM performs better on goals sampled from longer time horizons and when the goal pose is further away.
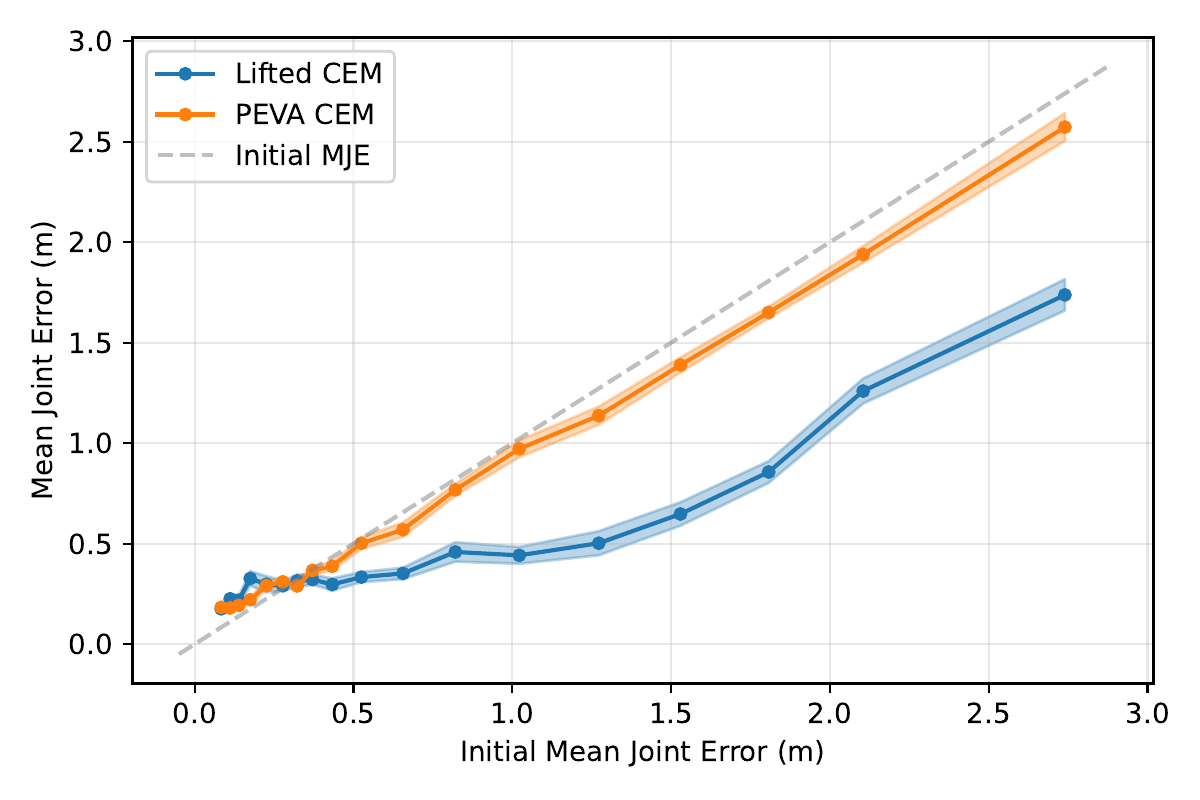
Takeaway
We present a method for lifting low-level world models to a higher level of abstraction by training a lightweight policy that maps high-level actions to sequences of low-level actions. We instantiate it for a human-like embodiment using a PEVA world model and a policy conditioned on high-level waypoints. Our approach is lightweight, requires no additional data, and works with off-the-shelf world models. Search-based planning with Lifted CEM is 3.8× more effective than planning in low-level joint space at various compute budgets and goal horizons. We believe that waypoints are one effective action space for egocentric, embodied agents, and moving forward the action spaces of world models will not only define what they learn, but how we use them.
BibTeX
@inproceedings{wang2026lifting,
title = {Lifting Embodied World Models for Planning and Control},
author = {Wang, Alex N. and Darrell, Trevor and Izmailov, Pavel
and Bai, Yutong and Bar, Amir},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2026},
note = {arXiv:2604.26182}
}